Java IO 读写原理
无论是 Socket 的读写还是文件的读写,在 Java 层面的应用开发或者 Linux 系统底层的开发,都属于输入(Input)和输出(Output)的处理,简称为 IO 读写。
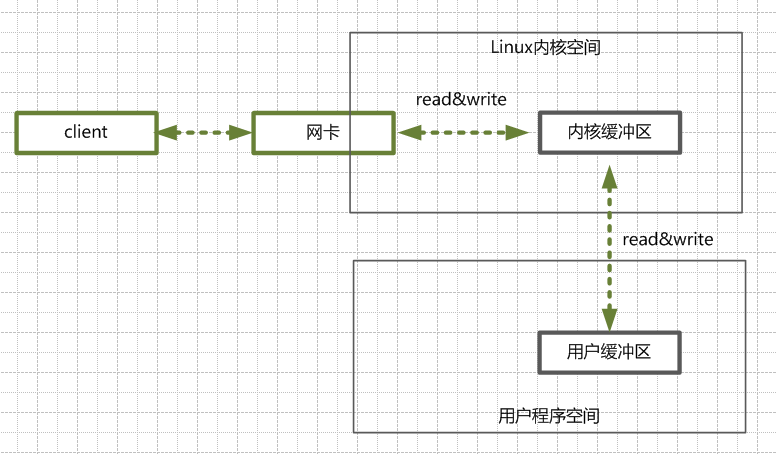
用户程序进行 IO 读写,基本都会用到 Read/Write 两大系统调用。
一个基础知识:Read 系统调用,并不是把数据直接从物理设备读到内存,Write 系统调用也不是直接把数据写入到物理设备。
- Read 系统调用,是把数据从内核缓冲区复制到进程缓冲区;
- Write 系统调用,是把数据从进程缓冲区复制到内核缓冲区。
这两个系统调用,都不负责数据在内核缓冲区和磁盘之前的交换,底层的读写交换,是由操作系统 Kernel 内核实现的。
内核缓冲区和进程缓冲区
系统调用前需要先保存之前的进程数据和状态等信息,结束调用后还需要恢复之前的数据,为了减少这种损耗时间、损耗性能的系统调用,于是出现的缓冲区。
在 Linux 系统中,系统内核有个内核缓冲区;每个进程有自己的进程缓冲区。
有了缓冲区,操作系统使用 Read 函数把数据从内核缓冲区复制到进程缓冲区,Write 函数把数据从进程缓冲区复制到内核缓冲区中。数据不是实时进行 IO,而是暂存在缓冲区,等缓冲区数据达到一定量的时候,再进行 IO 调用,提升性能。
Java IO 读写的底层流程
用户程序进行 IO 的读写,基本上会用到系统调用 Read、Write,系统调用的时候,数据在内核缓冲区和进程缓冲区之间交换,不等价于数据在内核缓冲区和磁盘之间的交换。
四种主要的 IO 模型
- 同步阻塞 IO (Blocking IO)
- 同步非阻塞 IO (Non-Blocking IO)
- IO 多路复用 (IO Multiplexing)
- 异步 IO (Asynchronous IO)
同步阻塞 IO (Blocking IO)
在 Linux 的 Java 进程中,默认情况下所有的 socket 都是 Blocking IO。在这种模型中,用户进程冲 IO 系统调用开始,一直到系统调用返回,这段时间都是阻塞的。
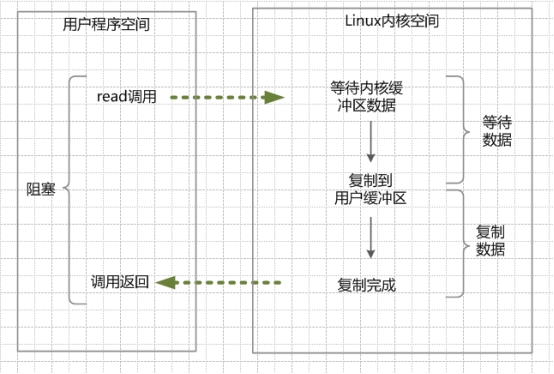
BIO 特点:
用户进程的线程发起系统调用,内核进行 IO 执行的两个阶段,用户线程都被阻塞了。
BIO 优点:
程序简单,在阻塞等待数据期间,用户线程挂起,基本不会占用 CPU 资源。
BIO 缺点:
一般情况线,每个连接配置一个独立的线程,这在并发量小的情况下,没什么问题。但是,在高并发场景下,需要大量的线程来维护大量的连接,内存、线程切换开销会非常巨大,基本上,BIO 在高并发场景下是不可用的。
同步非阻塞 IO (None Blocking IO)
在 Linux 系统下,可以设置使 socket 变为 non-blocking IO,这种模型一旦开始系统调用,会出现以下两种情况:
- 在内核缓冲区没有数据的情况下,系统调用立即返回,返回一个调用失败的信息。
- 在内核缓冲区有数据的情况下,是阻塞的,直到数据从内核缓冲区复制进用户进程缓冲区,复制完成,系统调用返回成功。
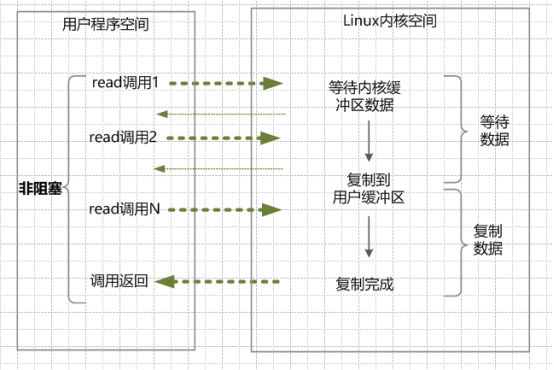
NIO 特点:
用户程序的线程需要不断的进行 IO 系统调用,轮询数据是否准备好,如果没有准备好,继续轮询,直到完成系统调用为止。
NIO 优点:
每次发起系统调用,在内核等待数据过程中可以立即返回,用户线程不会被阻塞,实时性较好。
NIO 缺点:
同一个线程,需要不断的重复发起系统调用,这种轮询,将会不断地询问内核,将占用大量的 CPU 时间,系统资源利用率较低。
tips: 强调一下,Java NIO(New IO) 不是 IO 模型中的 NIO 模型,而是另外一种模型,叫做 IO 多路复用模型(IO Multiplexing)。
IO 多路复用 (IO Multiplexing)
为了避免同步非阻塞中轮询等待的问题,出现了一种优化方案,这就是 IO 多路复用 (IO Multiplexing)。
IO 多路复用模型,就是通过一种新的系统调用,一个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核就能够通知程序进行相应的系统调用。
目前支持 IO 多路复用的系统调用有 select、poll、epoll。select 系统调用在目前几乎所有的操作系统上都有支持,具有良好的跨平台性,epoll 系统调用是在 Linux2.6 内核中率先实现的,是 select 系统调用的 Linux 增强版本。
IO 多路复用的基本原理:单个线程不断的轮询 select、poll、epoll 系统调用所负责的成百上千个 socket 连接,当某个或某些 socket 网络连接的数据到达了,就返回这些可以读写的连接。因此,通过一次 select、poll、epoll 系统调用,就能查询到可以读写的一个甚至成百上千个网络连接。
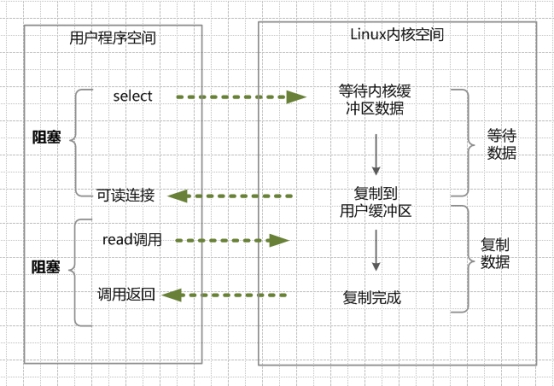
IO 多路复用特点:
IO 多路复用,建立在操作系统内核能够提供多路分离系统调用 select、poll、epoll 的基础上,该模型下的程序需要用到两个系统调用,一个 select、poll、epoll 查询调用,一个 IO 读写调用。
和 NIO 模型一样,IO 多路复用也需要轮询,负责 select、poll、epoll 查询调用的线程,需要不断的轮询,查出可以进行 IO 操作的连接,不同的是一次查询能查成百上千连接。
另外,IO 多路复用和 NIO 是有关系的,对于每一个查询的 socket,一般都设置成 non-blocking,只是这一点对用户是透明的。
IO 多路复用优点:
可以同时处理成千上万个连接,与一条线程对应一个连接相比,系统不必创建线程,也不必维护这些线程,从而大大减少了系统的开销。
IO 多路复用缺点:
本质上,select、poll、epoll 系统调用,属于同步 IO,也是阻塞的,都需要在读写的数据就绪后,自己负责读写,也就是说这个读写过程是阻塞的。
异步 IO (Asynchronous IO)
为了优化掉最后一点阻塞,于是出现了异步 IO (Asynchronous IO),简称为 AIO。
异步 IO 的基本流程:用户线程发起系统调用,告知内核启动某个 IO 操作,内核立即将调用结果返回。同时,内核开始进行 IO 操作(包含数据准备、数据复制),内核 IO 操作完成后,通知用户程序(信号、状态、回调函数等),用户程序再进行后续的读写操作。
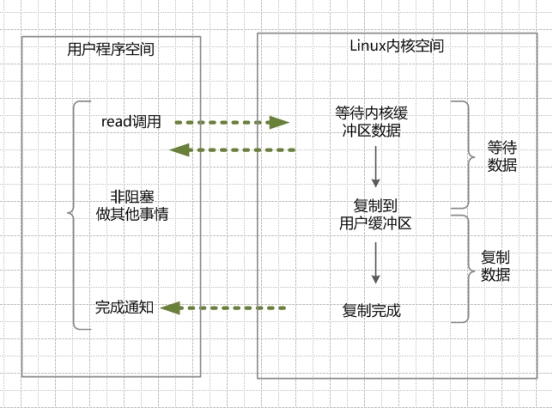
异步 IO 特点:
在接收到用户线程的 IO 操作请求,内核准备数据、复制数据的两个阶段,用户线程都是非阻塞的,用户线程只有接收到内核的通知,才进行下一步的读写操作。
异步 IO 缺点:
需要完成事件的注册与传递,这需要底层操作系统提供大量的支持,去做大量的工作。
目前来说,Windwos 系统下通过 IOCP 实现了真正的异步 IO,但是目前 Windows 系统很少作为百万级以上或者说高并发应用的服务器操作系统来使用。
而在 Linux 系统下,异步 IO 在 2.6 版本才引入,目前并不完善。所以,这也是在 Linux 下,实现高并发网络编程时都是以 IO 多路复用为主。
总结
四种 IO 模型,理论上越往后,阻塞越少,效率也是最优。在四种 IO 模型中,前三种属于同步 IO,因为其中真正的 IO 操作将阻塞线程,只有最后一种,才是真正的异步 IO 模型,可惜目前 Linux 尚欠完善。